
O nouă tehnologie ar putea într-o zi să ajute persoanele care nu pot vorbi din cauza unor tulburări neurologice să recâştige capacitatea de a comunica prin intermediul unei interfeţe creier-computer.
Imaginaţi-vă că ascultaţi o carte audio la jumătate de viteză. Aceasta este cea mai bună rată de decodare a vorbirii disponibilă în prezent, care se situează la aproximativ 78 de cuvinte pe minut, în timp ce, oamenii vorbesc aproximativ 150 de cuvinte pe minut.
„Există mulţi pacienţi care suferă de tulburări motorii debilitante, cum ar fi scleroza laterală amiotrofică (SLA) sau sindromul locked-in, care le pot afecta capacitatea de a vorbi", a declarat Gregory Cogan, profesor de neurologie la facultatea de medicină a Universităţii Duke şi unul dintre cercetătorii principali implicaţi în proiect.
El spune că, instrumentele actuale disponibile pentru a permite comunicarea sunt, în general, foarte lente şi greoaie.
Decalajul dintre ratele de vorbire naturală şi decodificată se datorează parţial numărului relativ mic de senzori de activitate cerebrală care pot fi fuzionaţi pe o bucată de material subţire ca hârtia care se aşează pe suprafaţa creierului. Mai puţini senzori oferă mai puţine informaţii descifrabile pentru decodare.
Pentru a îmbunătăţi aceste limitări laboratorul de inginerie biomedicală din cadrul Institutului pentru ştiinţa creierului de la Duke a realizat senzori cerebrali de înaltă densitate, ultra-subţiri şi flexibili.
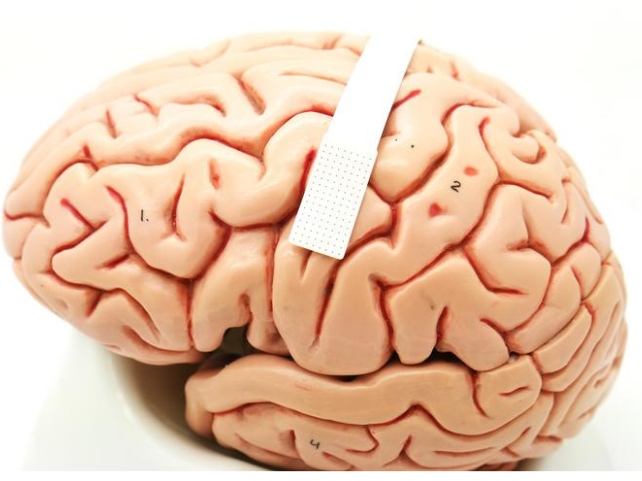
Foto articol: Reprezentarea senzorilor de pe dispozitiv - porţiunea punctată de pe banda albă. Credit: Dan Vahaba/Universitatea Duke)
Pentru acest proiect, echipa a împachetat un număr impresionant de 256 de senzori cerebrali microscopici pe o bucată de plastic flexibil, de calitate medicală, de mărimea unui timbru poştal.
Neuronii aflaţi la doar un grăunte de nisip distanţă unul de celălalt pot avea modele de activitate extrem de diferite atunci când coordonează vorbirea, astfel încât este necesar să poată distinge semnalele de la celulele cerebrale vecine pentru a ajuta la realizarea unor predicţii precise cu privire la vorbirea intenţionată.

Actuala proteză vocală cu 128 de electrozi (stânga) şi noul dispozitiv care găzduieşte de două ori mai mulţi senzori într-o matrice mult mai mică. Credit: Dan Vahaba/Universitatea Duke
După ce au fabricat noul implant, echipa a recrutat patru pacienţi pentru a testa implanturile.
În cadrul experimentului, cercetătorii au fost nevoiţi să plaseze temporar dispozitivul la pacienţii care erau supuşi unei intervenţii chirurgicale pe creier pentru o altă afecţiune, cum ar fi tratarea bolii Parkinson sau extirparea unei tumori.
Timpul a fost limitat pentru a testa dispozitivul în sala de operaţie.
„Nu vrem să adăugăm timp suplimentar la procedura chirurgicală, aşa că a trebuit să intrăm şi să ieşim în 15 minute. De îndată ce chirurgul şi echipa medicală au spus 'Start!', ne-am grăbit să intrăm în acţiune şi pacientul a îndeplinit sarcina", a explicat Cogan.
În timp ce micuţa matrice era implantată, echipa a putut înregistra activitatea din cortexul motor al creierului care transmite semnale către muşchii vorbirii în timp ce pacienţii repetau 52 de cuvinte fără sens.
„Non-cuvintele" au inclus nouă foneme diferite, cele mai mici unităţi de sunet care creează cuvintele vorbite.
Sarcina a fost o activitate simplă de tip „ascultă şi repetă". Participanţii au auzit o serie de cuvinte fără sens, cum ar fi „ava", „kug" sau „vip", iar apoi au rostit fiecare dintre ele cu voce tare.
Dispozitivul a înregistrat activitatea din cortexul motor al vorbirii fiecărui pacient în timp ce acesta coordona aproape 100 de muşchi care mişcă buzele, limba, maxilarul şi laringele.
Înregistrările au arătat că fonemele au provocat diferite modele de declanşare a semnalului şi s- observat că aceste modele de declanşare se suprapun ocazional unele peste altele, la fel cum muzicienii dintr-o orchestră îşi îmbină notele.
Acest lucru sugerează că creierul îşi ajustează dinamic discursul în timp real, pe măsură ce sunetele sunt emise.
Ulterior, echipa a luat datele neuronale şi de vorbire din sala de operaţie şi le-a introdus într-un algoritm de învăţare automată pentru a vedea cât de precis putea acesta prezice ce sunet era emis, bazându-se doar pe înregistrările activităţii cerebrale.
Pentru unele sunete, cum ar fi /g/ din cuvântul „gak", decodificatorul a nimerit în 84% din cazuri atunci când acesta era primul sunet dintr-un şir de trei care formau un anumit cuvânt fără sens.
Precizia a scăzut, totuşi, pe măsură ce decodorul a analizat sunetele din mijlocul sau de la sfârşitul unui cuvânt fără sens.
De asemenea, a întâmpinat dificultăţi în cazul în care două sunete erau similare, cum ar fi /p/ şi /b/.
În general, decodificatorul a fost precis în 40% din timp.
Acesta poate părea un scor modest, dar a fost destul de impresionant, având în vedere că performanţele tehnice similare de transformare a creierului în vorbire necesită ore sau zile întregi de date pentru a fi utilizate.
Cu toate acestea, algoritmul de decodare a vorbirii folosit a lucrat cu doar 90 de secunde de date vorbite din testul de 15 minute.
Echipa a primit recent fonduri de 2,4 milioane de dolari de la Institutele Naţionale de Sănătate (NIH), din Statele Unite, pentru a realiza o versiune fără fir a dispozitivului, la care echipa lucrează în prezent.
„Suntem în punctul în care este încă mult mai lent decât vorbirea naturală", au declarat autorii într-un articol recent al revistei Duke Magazine care a descris această tehnologie, „dar se poate vedea traiectoria pe care s-ar putea ajunge acolo".
Studiul a fost publicat recent în revista Nature Communications.
[ot-video][/ot-video]




